Cloud Java Stack
Cloud Java Stack
Capa主要面向Java语言进行设计。
Capa本身不提供功能,而是由底层的各种中间件的Java SDK来提供。
所以了解Java中常用中间件的设计是很有必要的。
本目录主要为对Java生态中中间件的学习和实践。
Dubbo Stack
Dubbo Invoke流程
概要
梳理Dubbo的调用链路流程,分析其设计理念和思路,以及阅读其中关键步骤的源码逻辑
Review
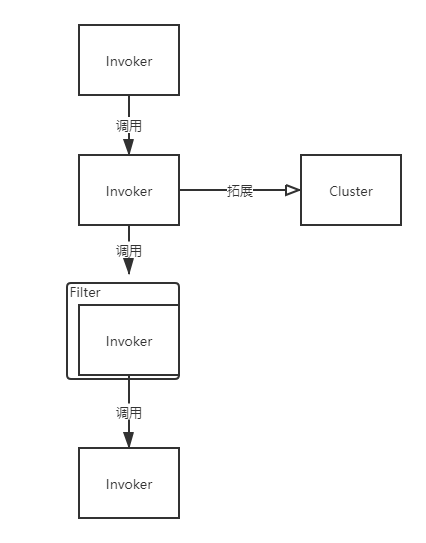
在 RPC 中,Protocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用,然后在 Invoker 的主过程上 Filter 拦截点。
调用流程主要围绕Protocol/Invoker/Filter三个接口进行
public interface Protocol {
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
public interface Invoker<T> extends Node {
Result invoke(Invocation invocation) throws RpcException;
void destroy();
}
public interface Filter extends BaseFilter {
Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException;
}
整体流程
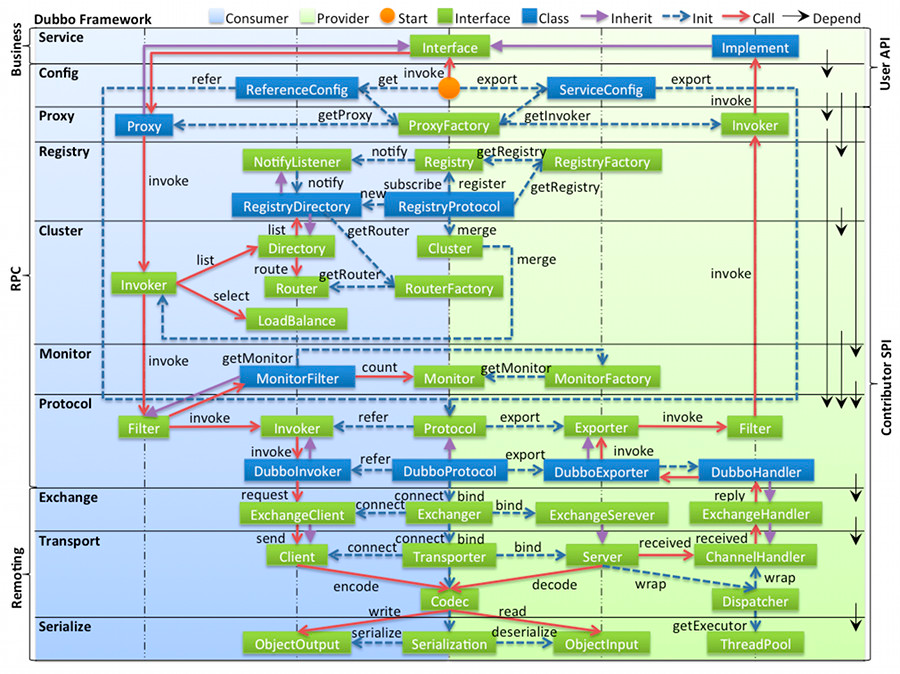
初始化流程
- 初始化配置相关…….
- 初始化
Protocol - 初始化
Invoker - 初始化底层资源
调用流程
- 调用
Invoker,做一些逻辑 - 调用
Filter,做一些逻辑 - 调用
Invoker,做一些逻辑 - 调用底层资源
简化设计
从一个Client开始……
1. 直接调用
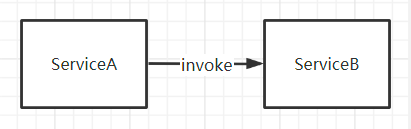
2. 责任链模式
解决函数逻辑的水平拓展问题

定义接口:Response invoke(Request request);
public interface Invoker<T> extends Node {
Result invoke(Invocation invocation) throws RpcException;
void destroy();
}
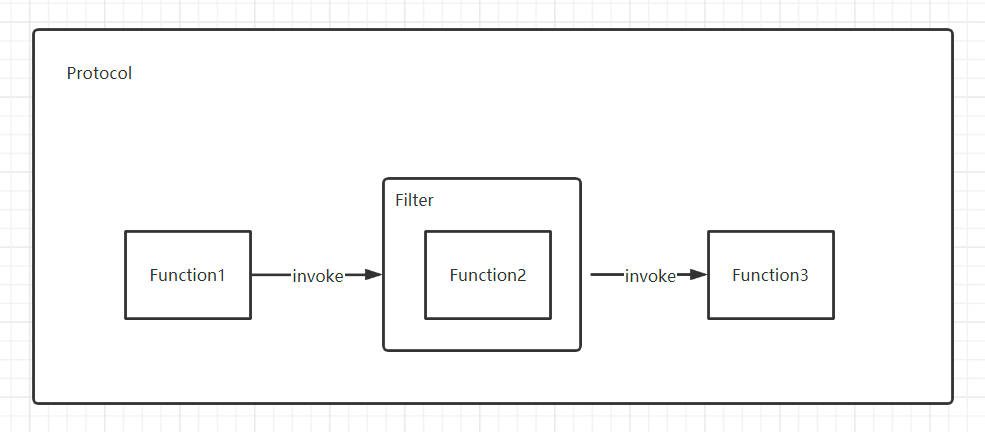
3. 过滤器插件
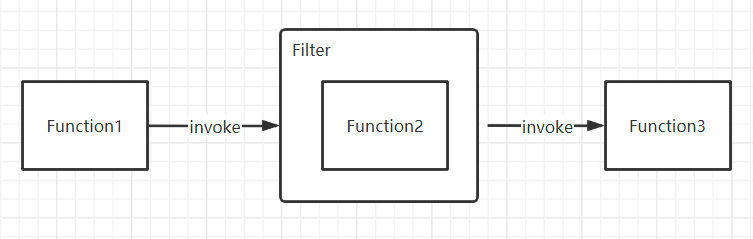
在重要的过程上设置拦截接口
如果你要写个远程调用框架,那远程调用的过程应该有一个统一的拦截接口。如果你要写一个 ORM 框架,那至少 SQL 的执行过程,Mapping 过程要有拦截接口;如果你要写一个 Web 框架,那请求的执行过程应该要有拦截接口,等等。没有哪个公用的框架可以 Cover 住所有需求,允许外置行为,是框架的基本扩展方式。这样,如果有人想在远程调用前,验证下令牌,验证下黑白名单,统计下日志;如果有人想在 SQL 执行前加下分页包装,做下数据权限控制,统计下 SQL 执行时间;如果有人想在请求执行前检查下角色,包装下输入输出流,统计下请求量,等等,就可以自行完成,而不用侵入框架内部。拦截接口,通常是把过程本身用一个对象封装起来,传给拦截器链,比如:远程调用主过程为 invoke(),那拦截器接口通常为 invoke(Invocation),Invocation 对象封装了本来要执行过程的上下文,并且 Invocation 里有一个 invoke() 方法,由拦截器决定什么时候执行,同时,Invocation 也代表拦截器行为本身,这样上一拦截器的 Invocation 其实是包装的下一拦截器的过程,直到最后一个拦截器的 Invocation 是包装的最终的 invoke() 过程;同理,SQL 主过程为 execute(),那拦截器接口通常为 execute(Execution),原理一样。当然,实现方式可以任意,上面只是举例。
public interface Filter extends BaseFilter {
Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException;
}
装饰模式/组合模式
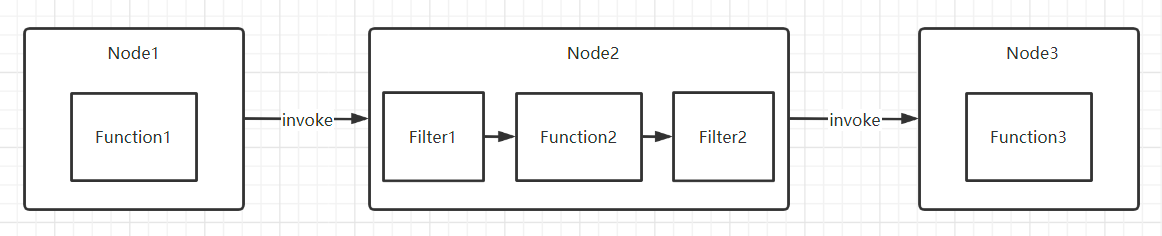
4. 领域模型的设计
重资源 -> 资源的管理 -> 生命周期
资源的管理:
共享、创建、释放、生命周期……..
链路治理、上下文、组装……..
领域模型
在 Dubbo 的核心领域模型中:
- Protocol 是服务域,它是 Invoker 暴露和引用的主功能入口,它负责 Invoker 的生命周期管理。
- Invoker 是实体域,它是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
- Invocation 是会话域,它持有调用过程中的变量,比如方法名,参数等。
public interface Protocol {
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
共享资源谁持有?
缓存在哪里存储?
线程安全?
单例还是New?
服务域/实体域/会话域分离
任何框架或组件,总会有核心领域模型,比如:Spring 的 Bean,Struts 的 Action,Dubbo 的 Service,Napoli 的 Queue 等等。这个核心领域模型及其组成部分称为实体域,它代表着我们要操作的目标本身。实体域通常是线程安全的,不管是通过不变类,同步状态,或复制的方式。 ①
服务域也就是行为域,它是组件的功能集,同时也负责实体域和会话域的生命周期管理, 比如 Spring 的 ApplicationContext,Dubbo 的 ServiceManager 等。服务域的对象通常会比较重,而且是线程安全的,并以单一实例服务于所有调用。 ②
什么是会话?就是一次交互过程。会话中重要的概念是上下文,什么是上下文?比如我们说:“老地方见”,这里的“老地方”就是上下文信息。为什么说“老地方”对方会知道,因为我们前面定义了“老地方”的具体内容。所以说,上下文通常持有交互过程中的状态变量等。会话对象通常较轻,每次请求都重新创建实例,请求结束后销毁。简而言之:把元信息交由实体域持有③,把一次请求中的临时状态由会话域持有,由服务域贯穿整个过程。
① Invoker仅维护自己的状态,类似Actor设计模式
② Protocol初始化为单例,并且持有缓存Map
③ Invoker中存储默认元信息,临时信息存储到Invocation
=> show code
4.1 资源的销毁
由服务域管理资源的生命周期,并委托给实体域执行
public interface Protocol {
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
public interface Invoker<T> extends Node {
Result invoke(Invocation invocation) throws RpcException;
void destroy();
}
4.2 状态的监听
重要的状态的变更发送事件并留出监听接口
这里先要讲一个事件和上面拦截器的区别,拦截器是干预过程的,它是过程的一部分,是基于过程行为的,而事件是基于状态数据的,任何行为改变的相同状态,对事件应该是一致的。事件通常是事后通知,是一个 Callback 接口,方法名通常是过去式的,比如 onChanged()。比如远程调用框架,当网络断开或连上应该发出一个事件,当出现错误也可以考虑发出一个事件,这样外围应用就有可能观察到框架内部的变化,做相应适应。
public interface InvokerListener {
void referred(Invoker<?> invoker) throws RpcException;
void destroyed(Invoker<?> invoker);
}
4.3 纵向拓展
SPI,微内核,插件化
微核插件式,平等对待第三方
大凡发展的比较好的框架,都遵守微核的理念。Eclipse 的微核是 OSGi, Spring 的微核是 BeanFactory,Maven 的微核是 Plexus。通常核心是不应该带有功能性的,而是一个生命周期和集成容器,这样各功能可以通过相同的方式交互及扩展,并且任何功能都可以被替换。如果做不到微核,至少要平等对待第三方,即原作者能实现的功能,扩展者应该可以通过扩展的方式全部做到。原作者要把自己也当作扩展者,这样才能保证框架的可持续性及由内向外的稳定性。
引入配置模块,担当微内核。并负责Protocol的初始化启动(Protocol再负责下层的初始化)
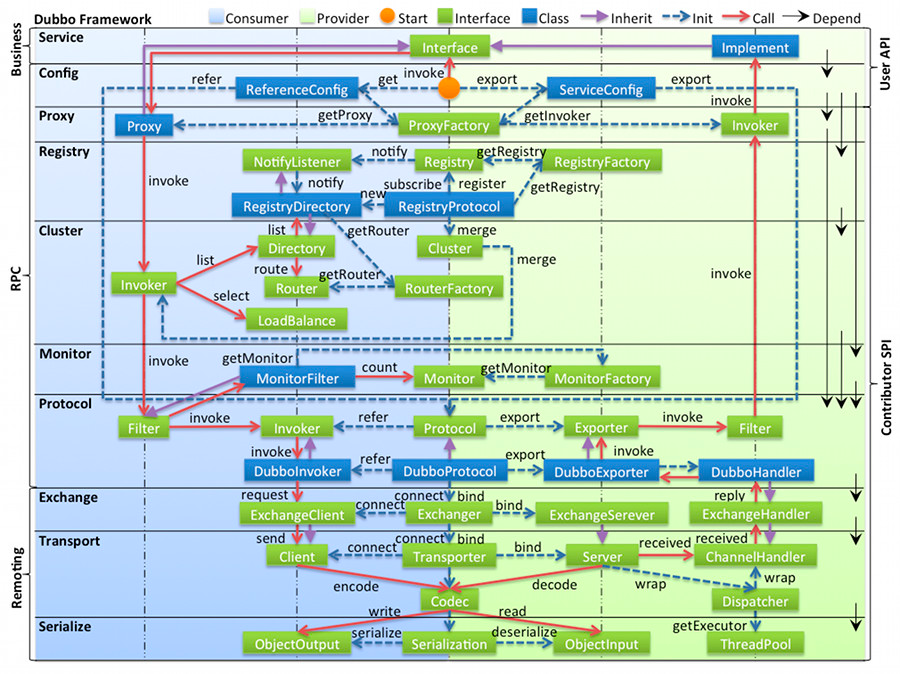
4.4 完善的分层
- config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类
- proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory
- registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService
- cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance
- monitor 监控层:RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService
- protocol 远程调用层:封装 RPC 调用,以 Invocation, Result 为中心,扩展接口为 Protocol, Invoker, Exporter
- exchange 信息交换层:封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer
- transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec
- serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool
其他层次以插件的方式装配到config里,核心仍然是Protocol层。功能要么伪装成Invoker,要么在初始化时进行。
在 RPC 中,Protocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用,然后在 Invoker 的主过程上 Filter 拦截点。

层级关系:
-system
-config
-proxy
-registry
-cluster
-monitor
-protocol
-invoker
-exchange
-...
5. 异步调用
public interface Result extends Serializable {
Result whenCompleteWithContext(BiConsumer<Result, Throwable> fn);
}
重点关注点
结合一开始的大概流程…
1. protocol初始化流程
初始化的时候做了什么?集群?注册发现?代理封装?
资源如何加载?如何缓存?连接池?线程池?
……..
2. invoke流程
实际调用过程的流程?有哪些逻辑步骤?
负载均衡?重试?监控?序列化?
同步异步?流式调用?
……..
Invoke流程解读
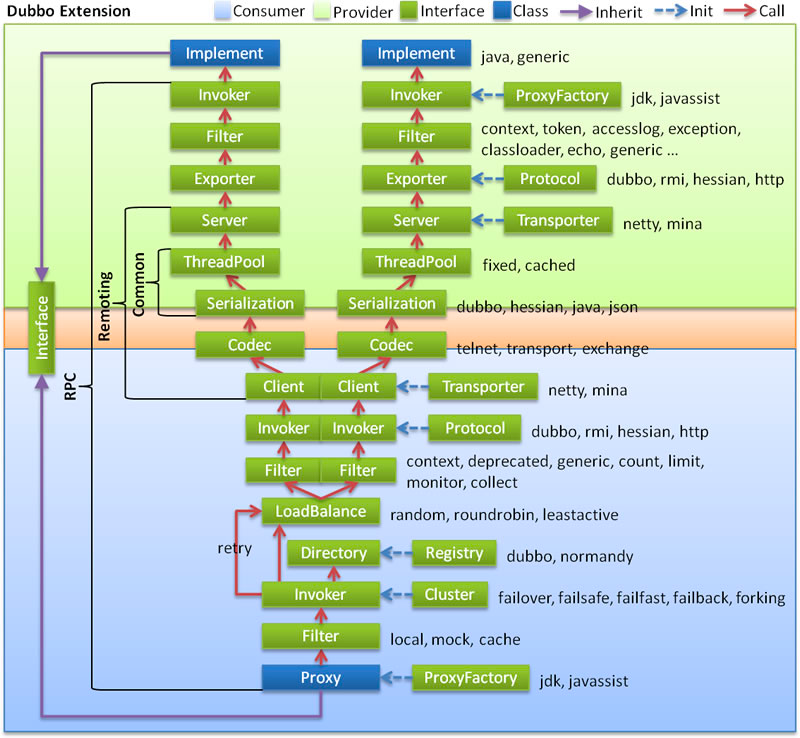
调用流程
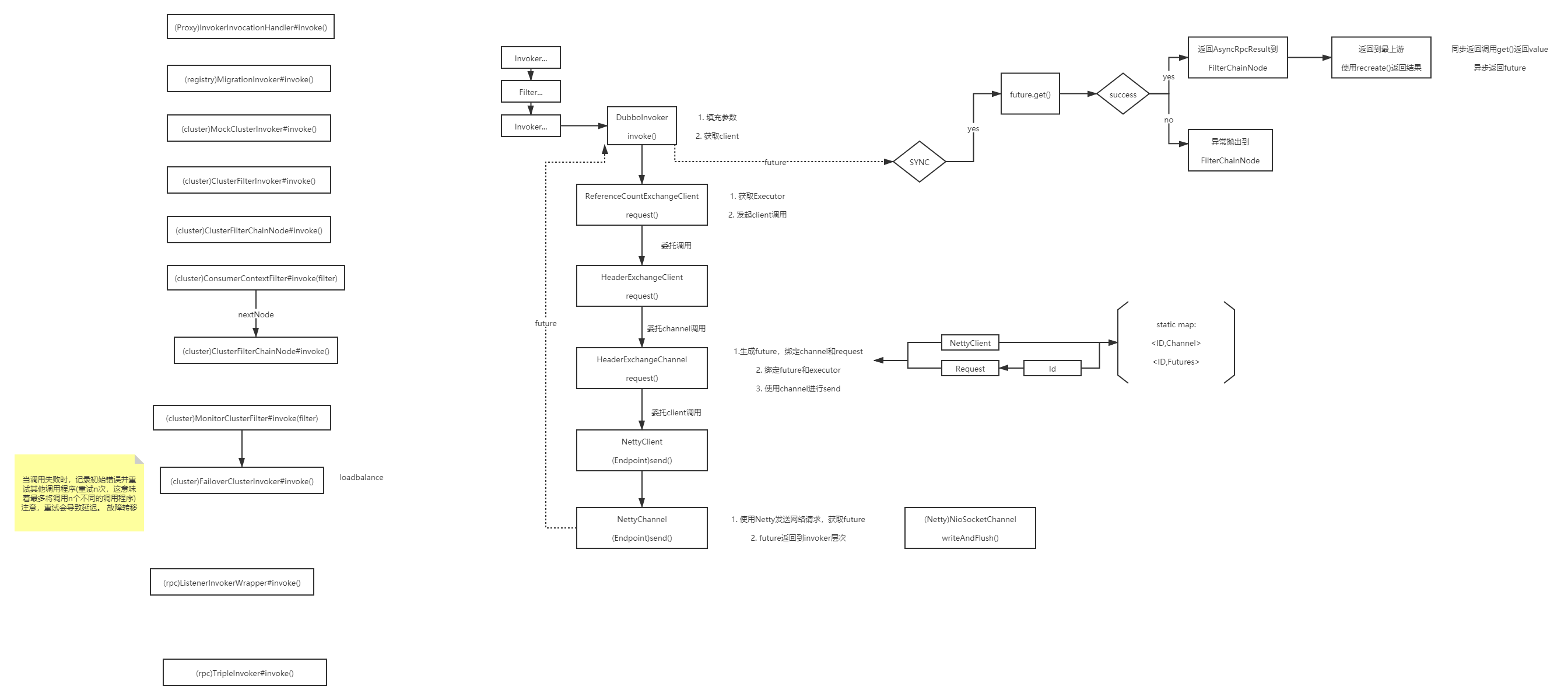
源码分析
关键Invoker的逻辑:
AbstractInvoker: 3个步骤,(PR:https://github.com/apache/dubbo/pull/7952)
具体逻辑在doInvoke中
FailoverClusterInvoker
当调用失败时,记录初始错误并重试其他调用程序(重试n次,这意味着最多将调用n个不同的调用程序)注意,重试会导致延迟。 故障转移
图中方法:list、route、select
什么时候会重试?非biz异常,但粒度很粗….(Issue相关)
ListenerInvokerWrapper
注册invoker的listener,并进行操作,装饰模式
改进:观察者模式+生命周期
FilterChainNode
实际上是Invoker,但内部保存了Filter
Invoker装饰,Filter适配,两者的组合
DubboInvoker
可以看到:Invoker层持有下层的资源管理
接下来就是excahnge层的逻辑
TripleInvoker
直接持有底层netty资源,比较粗糙
=> show code
总结
1.层次结构
层级关系:
-system
-config
-proxy
-registry
-cluster
-monitor
-protocol
-invoker
-exchange
-...
2.调用流程
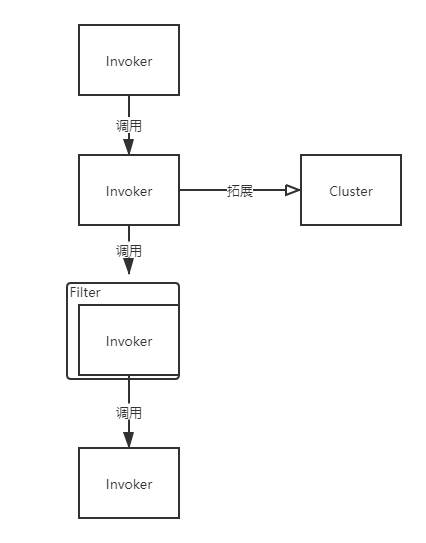
3.设计模式
责任链:Invoker
适配器:适配到Invoker责任链中
装饰:对Invoker进行增强
………
4.设计优化
Invoker调用链:√,整个系统的核心,插件化功能采用拓展接口的方式,各个模块功能比较明确
Lifecycle生命周期:不完全,没有完整的生命周期;对于生命周期的事件处理比较硬编码
Listener:装饰的比较硬编码,事件阶段不够全,拓展性不够好
Filter:采用装饰模型而非组合模型,拓展性较差;嵌套层级深,调试时链路不清晰
……..
Dubbo Landscape
一、Dubbo整体设计概述
A、Invoker责任链设计
B、Filter拓展机制设计
C、Manager容器管理设计
D、Listener监听器设计
E、Lifecycle生命周期设计
二、设计思想
A、可拓展架构
SPI,微内核,插件化
B、设计模式
装饰器模式
责任链模式
C、DDD设计
Java Web Stack
Java Servlet
A、初始化
https://www.codetd.com/en/article/13249666#ServletContextListener_27
ServletContextListener
ServletContextListener 接口,它能够监听 ServletContext 对象的生命周期,当Servlet 容器启动或终止Web 应用时,会触发ServletContextEvent 事件,该事件由ServletContextListener 来处理。
Java Spring
A、初始化
https://www.codetd.com/en/article/13249666#ServletContextListener_27
BeanPostProcessor
Spring容器的创建Bean前后执行
InitializingBean
InitializingBean接口为bean提供了属性初始化后的处理方法,在bean的属性初始化后都会执行该方法。
PostConstruct
使用@PostConstruct注解一个方法来完成初始化,@PostConstruct注解的方法将会在依赖注入完成后被自动调用。
ApplicationRunner和CommandLineRunner
项目启动后执行,CommandLineRunner和ApplicationRunner的作用是相同的,不同在于参数的封装和没封装。可以创建多个实现CommandLineRunner和ApplicationRunner接口的类。为了使他们按一定顺序执行,可以使用@Order注解或实现Ordered接口。
执行顺序结果
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v1.5.9.RELEASE)
beanPostProcessor run...
servletContextListener run...
initializingBean run...
postConstruct run...
applicationRunner run...
commandLineRunner run...
Netty Stack
Netty Channel设计
一、整体流程概览
……
1.1 启动流程
Server端
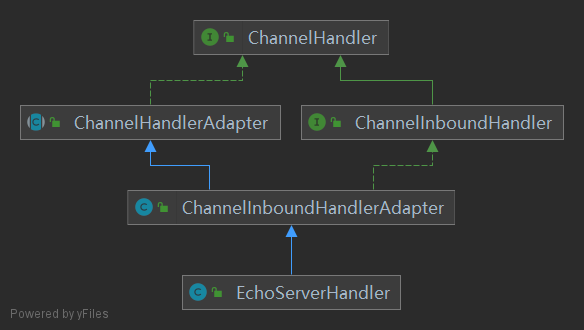
1. 创建Handler
EchoServerHandler serverHandler = new EchoServerHandler()
Handler类结构图:
2. 创建EventLoopGroup
EventLoopGroup group = new NioEventLoopGroup();
EventLoopGroup类结构图:
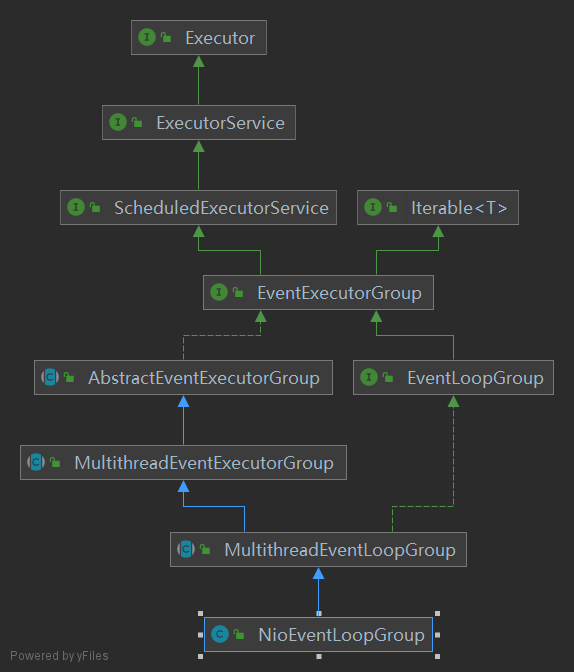
2.1 创建Group下面的EventLoop
@Override
protected EventLoop newChild(Executor executor, Object... args) throws Exception {
return new NioEventLoop(this, executor, (SelectorProvider) args[0],
((SelectStrategyFactory) args[1]).newSelectStrategy(), (RejectedExecutionHandler) args[2]);
}
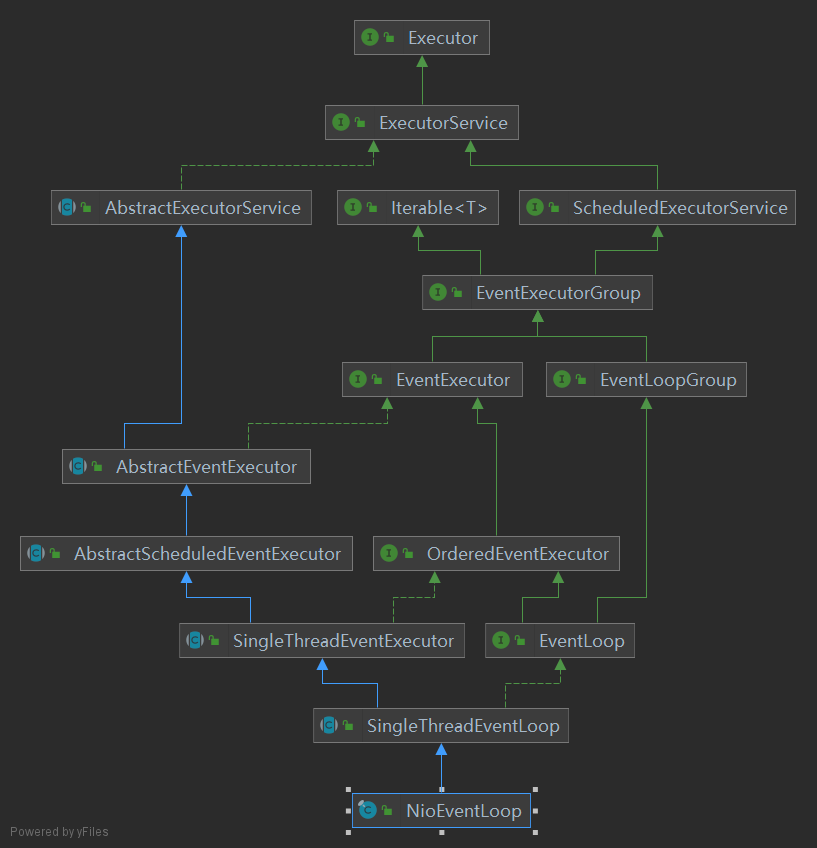
2.2 创建EventLoop
taskQueue:MpscChunkedArrayQueuetailQueue:MpscChunkedArrayQueueselectNowSupplier:selector.selectNow()pendingTasksCallable:super.pendingTasks() + tailTasks.size()selectProvider:SelectorProvider.provider()
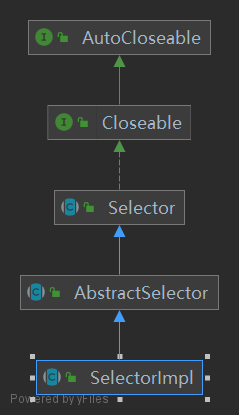
3. 创建引导
ServerBootstrap b = new ServerBootstrap();
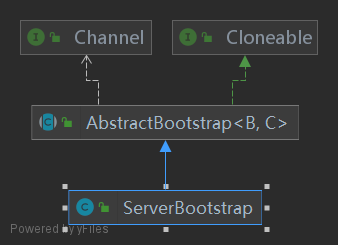
3.1 初始化一个Channel
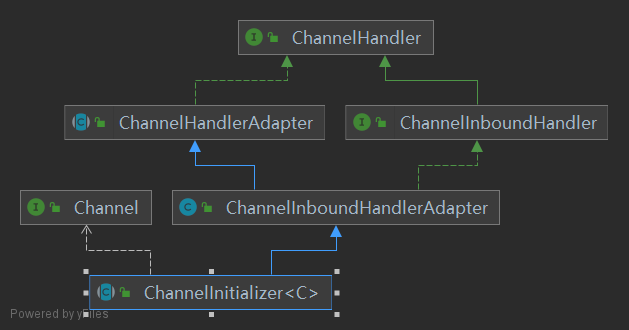
4. bind流程
4.1 初始化一个Channel
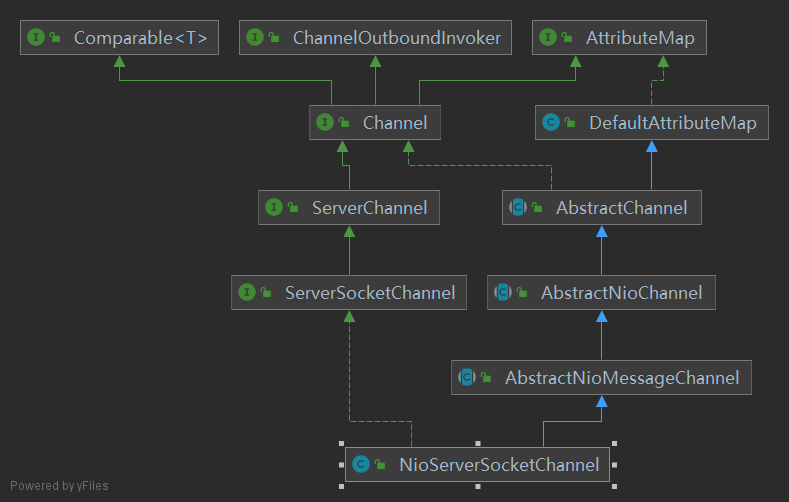
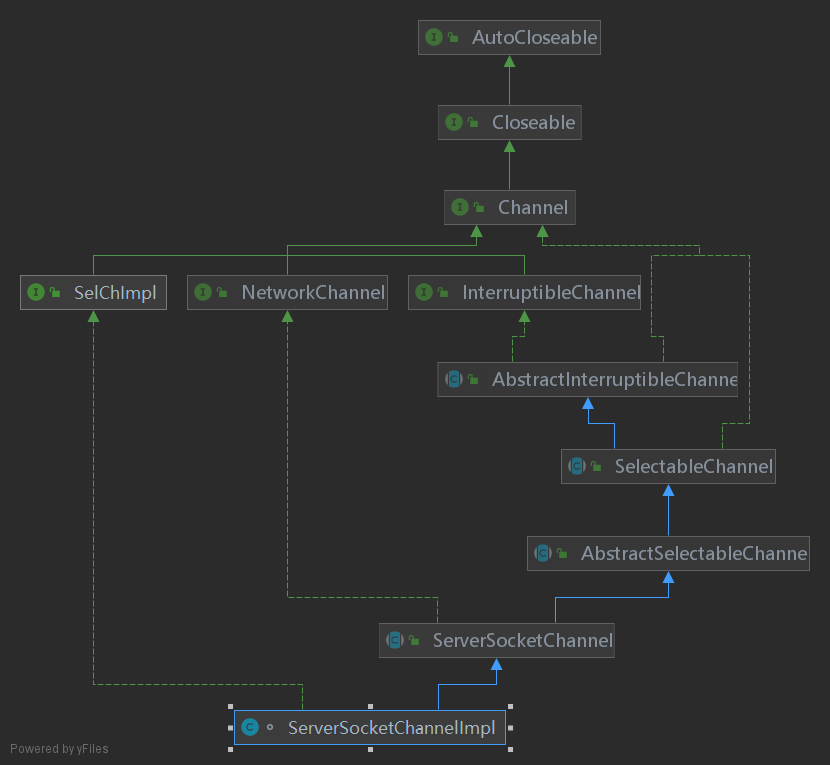
持有底层的SocketChannel:(此处的Channel为java.nio的Channel)
4.2 初始化ChannelPipeline
创建一个DefaultChannelPipeline:
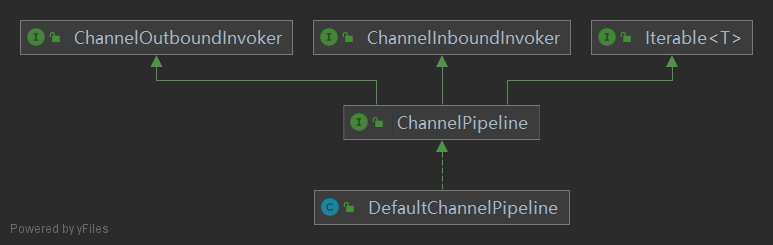
Channel和ChannelPipeline是双向绑定的关系,向ChannelPipeline中通过addLast方法添加Handler。
将ChannelHandler包装进入ChannelContext, 然后ChannelPipeline持有ChannelContext的双向链表:
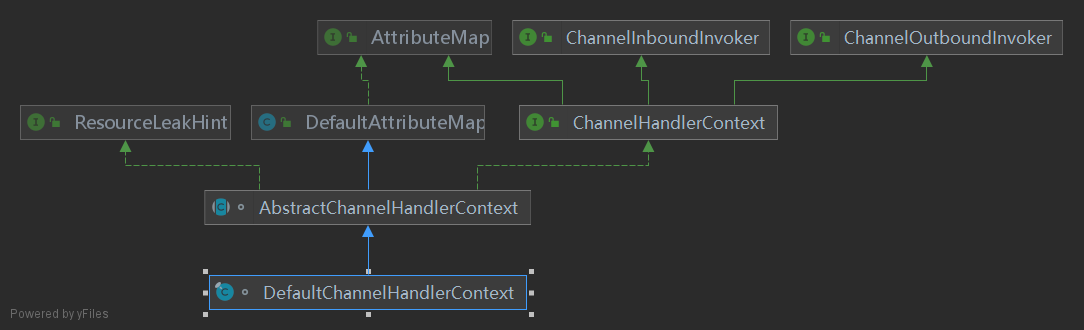
4.3 注册ChannelFuture
ChannelFuture:对Channel的各个生命周期阶段注册回调
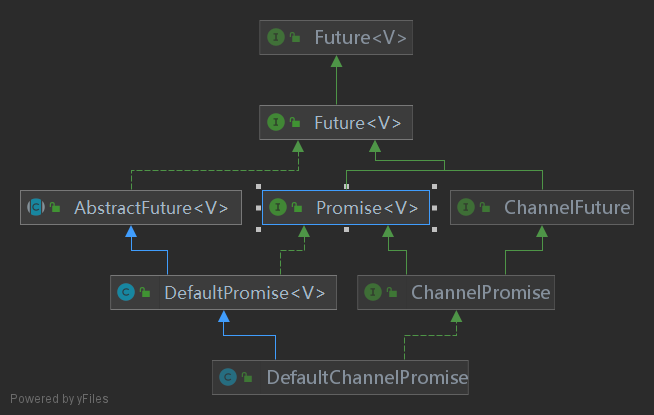
调用的是AbstractChannel的:
public final void register(EventLoop eventLoop, final ChannelPromise promise) {
然后是:
eventLoop.execute(new Runnable() {
@Override
public void run() {
register0(promise);
}
});
eventloop在这里是前面创建的EventLoopGroup
4.4 register0()解析
- pipeline.invokeHandlerAddedIfNeeded();
执行前面注册的ChannelHandler初始化initChannel的动作
- 第一个Handler执行完成后,会再次提交一个Runnable给EventLoop
ServerBootstrapAcceptor
- EventLoop不断执行Task(该部分需要细化)
最终进入bind()操作,执行ServerSocketChannelImpl.bind()
Client端
1. 启动流程
同Server
2. connect流程
connect操作会注册一个task给eventloop
eventloop执行task:
Bootstrap.doResolveAndConnect0()doConnect()
channel.connect()
SocketChannelImpl.connect()
interestOps置为8
3. ClientHandler
- channelActive()
- channelRead()
1.2 事件驱动模型设计
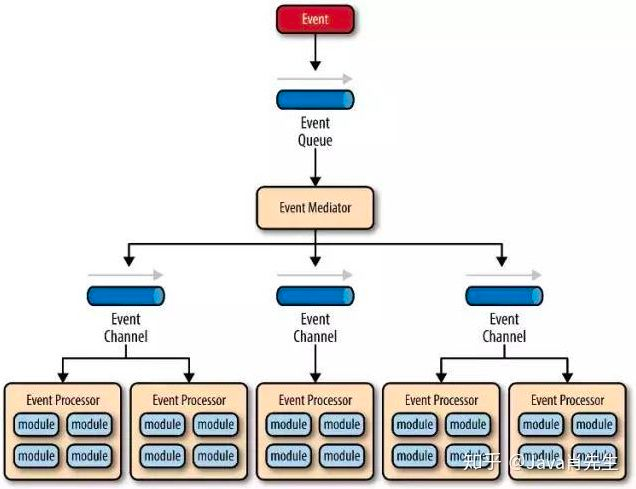
主要包括4个基本组件:
事件队列(event queue):接收事件的入口,存储待处理事件
分发器(event mediator):将不同的事件分发到不同的业务逻辑单元
事件通道(event channel):分发器与处理器之间的联系渠道
事件处理器(event processor):实现业务逻辑,处理完成后会发出事件,触发下一步操作
可以看出,相对传统轮询模式,事件驱动有如下优点:
- 可扩展性好,分布式的异步架构,事件处理器之间高度解耦,可以方便扩展事件处理逻辑
- 高性能,基于队列暂存事件,能方便并行异步处理事件
在同一组会话/链接中,将会触发不同的事件入口时,适合事件驱动架构
二、主要模块
2.1 Reactor线程模型
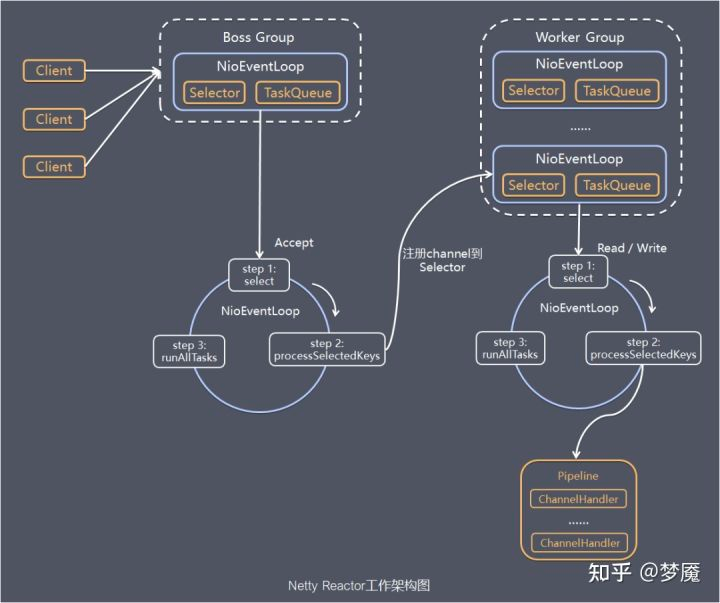
1)Netty 抽象出两组线程池:BossGroup 和 WorkerGroup,也可以叫做 BossNioEventLoopGroup 和 WorkerNioEventLoopGroup。每个线程池中都有 NioEventLoop 线程。BossGroup 中的线程专门负责和客户端建立连接,WorkerGroup 中的线程专门负责处理连接上的读写。BossGroup 和 WorkerGroup 的类型都是 NioEventLoopGroup。
2)NioEventLoopGroup 相当于一个事件循环组,这个组中含有多个事件循环,每个事件循环就是一个 NioEventLoop。
3)NioEventLoop 表示一个不断循环的执行事件处理的线程,每个 NioEventLoop 都包含一个 Selector,用于监听注册在其上的 Socket 网络连接(Channel)。
4)NioEventLoopGroup 可以含有多个线程,即可以含有多个 NioEventLoop。
5)每个 BossNioEventLoop 中循环执行以下三个步骤:
5.1)select:轮训注册在其上的 ServerSocketChannel 的 accept 事件(OP_ACCEPT 事件)
5.2)processSelectedKeys:处理 accept 事件,与客户端建立连接,生成一个 NioSocketChannel,并将其注册到某个 WorkerNioEventLoop 上的 Selector 上
5.3)runAllTasks:再去以此循环处理任务队列中的其他任务
6)每个 WorkerNioEventLoop 中循环执行以下三个步骤:
6.1)select:轮训注册在其上的 NioSocketChannel 的 read/write 事件(OP_READ/OP_WRITE 事件)
6.2)processSelectedKeys:在对应的 NioSocketChannel 上处理 read/write 事件
6.3)runAllTasks:再去以此循环处理任务队列中的其他任务
7)在以上两个processSelectedKeys步骤中,会使用 Pipeline(管道),Pipeline 中引用了 Channel,即通过 Pipeline 可以获取到对应的 Channel,Pipeline 中维护了很多的处理器(拦截处理器、过滤处理器、自定义处理器等)。这里暂时不详细展开讲解 Pipeline。
2.2 ChannelPipeline设计
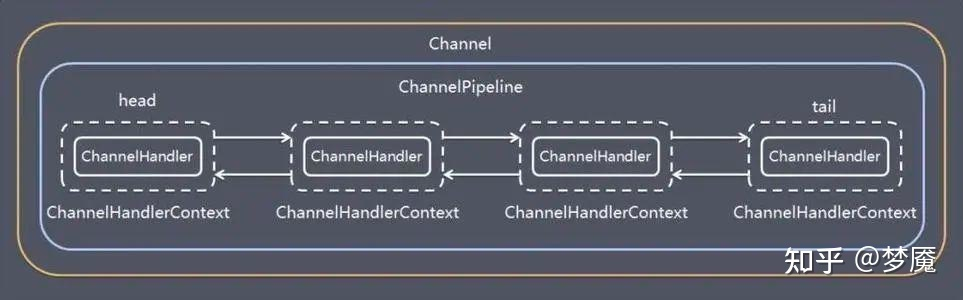
1)Bootstrap 和 ServerBootstrap 分别是客户端和服务器端的引导类,一个 Netty 应用程序通常由一个引导类开始,主要是用来配置整个 Netty 程序、设置业务处理类(Handler)、绑定端口、发起连接等。
2)客户端创建一个 NioSocketChannel 作为客户端通道,去连接服务器。
3)服务端首先创建一个 NioServerSocketChannel 作为服务器端通道,每当接收一个客户端连接就产生一个 NioSocketChannel 应对该客户端。
4)使用 Channel 构建网络 IO 程序的时候,不同的协议、不同的阻塞类型和 Netty 中不同的 Channel 对应,常用的 Channel 有:
NioSocketChannel:非阻塞的 TCP 客户端 Channel(本案例的客户端使用的 Channel) NioServerSocketChannel:非阻塞的 TCP 服务器端 Channel(本案例的服务器端使用的 Channel) NioDatagramChannel:非阻塞的 UDP Channel NioSctpChannel:非阻塞的 SCTP 客户端 Channel NioSctpServerChannel:非阻塞的 SCTP 服务器端 Channel…
每个 Netty Channel 包含了一个 ChannelPipeline(其实 Channel 和 ChannelPipeline 互相引用),而 ChannelPipeline 又维护了一个由 ChannelHandlerContext 构成的双向循环列表,其中的每一个 ChannelHandlerContext 都包含一个 ChannelHandler。(前文描述的时候为了简便,直接说 ChannelPipeline 包含了一个 ChannelHandler 责任链,这里给出完整的细节。)
2.3 Channel模块设计
1. 事件驱动 + 指令式设计 + 过程调用
网络Channel对象 + 执行器 + 不同的事件处理器
processor.execute(channel(data), executor(executore))
2. 事件驱动 + 对象设计 + 责任链
面向对象包装Channel:执行器、自身属性、操作定义
事件处理器责任链化:pipeline
事件处理器状态机:内部状态流转和外部状态触发 (好几套状态机…channel/pipeline/bootstrap…)
内部状态流转的例子:register->register0->doregister —future完成后—> bind->dobind0 内部状态流转:bind –> pipeline.fireChannelActive —> 一系列handler等内部状态流转 —> read –> 注册read状态位 –> 进入外部事件触发
register: 接口定义,事件入口 register0: 抽象类封装(递交给eventloop) doregister: 委托底层实现
3. channel接口交互
channel事件入口 --->递交给 channelpipeline(invoker定义链路操作) --->链路入口 channelhandler执行具体链路方法
--->上下文 channelcontext
channelpipelint: invoker+链路组装
佐证:channelpipeline(invoker)和handler的方法一一对应 推测:context:面向对象的封装、另开一条链路
ctx.fireChannelActive(); 链路控制
责任链需要递归无用的handler,通过context直接指向下一个执行者,优化了流程
三、细节功能
3.1 缓冲区/零拷贝
……
3.2 IO异步机制
……
3.3 网络协议
……
参考文章
IO 模型
Netty Landscape
一、Netty整体设计概述
A、Pipeline链设计
B、内外状态映射设计
C、Reactor线程模型
D、线程池分离
Boss Worker
二、设计思想
A、可拓展架构
B、命令模式
将待执行操作包装成命令对象,投递给eventloop线程执行
Reactive Stack
Reactive Landscape
一、Reactive Stream整体设计概述
A、声明式编程
B、延迟执行
单流
C、反向组装
三流
D、背压(反向订阅)
五流
二、设计思想
A、命令模式拓展
将步骤抽象为Sink算子
Reactive模式在Trip.com消息推送平台上的实践
原文地址:https://zhuanlan.zhihu.com/p/392401566
Reactor-Core 数据流模型设计
反应式编程理论与Reactor源码解析
反应式编程理论
反应式宣言
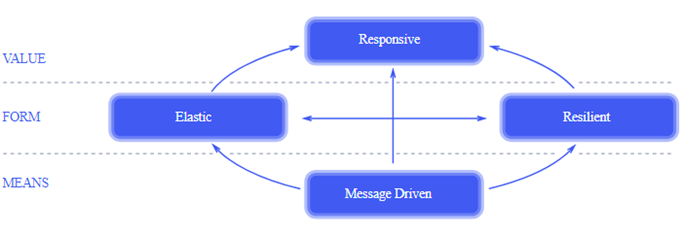
反应式宣言:异步 非阻塞 带回压 的方式进行流程控制
技术手段+表现形式:
- 异步非阻塞 → 相比基于回调和Future的异步开发模型,通过函数式编程和声明式编程更加具有可编排性和可读性。
- 回压机制 → 通过订阅模型,组装数据流的流水线,下游订阅者可以反压源头,将“推送”模式转换为“推送+拉取”混合的模式。
- 事件驱动 → 应用内事件循环,使用EventLoop线程模型,能够做到异步非阻塞
- 消息驱动 → 分布式系统通信和协作,使用反应式的网络通信协议
反应式编程适用场景
我们在选择使用反应式编程时,一定要明确它的适用场景,主要包括:
- 处理由用户或其他系统发起的事件,如鼠标点击、键盘按键或者物联网设备等无时无刻都在发射信号的情况
- 处理磁盘或网络等高延迟的IO数据,且保证这些IO操作是异步的
- 业务的处理流程是流式的,且需要高响应的非阻塞操作
仍然没有免费的午餐
首先,我们的代码是声明式的,不方便调试,错误发生时不容易定位。使用原生的API,例如不通过Spring框架而直接使用Reactor,会使情况变的更糟,因为我们自己要做很多的错误处理,每次进行网络调用都要写很多样板代码。通过组合使用 Spring 和 Reactor 我们可以方便的查看堆栈信息和未捕获的异常。由于运行的线程不受我们控制,因此在理解上会有困难。
其次,一旦编写错误导致一个Reactive回调被阻塞,在同一线程上的所有请求都会挂起。在servlet容器中,由于是一个请求一个线程,一个请求阻塞时,其它的请求不会受影响。而在Reactive中,一个请求被阻塞会导致所有请求的延迟都增加。
一、反应式编程库介绍
实践反应式宣言的编程框架,提供开箱即用的反应式编程手段
1.1 为什么要使用反应式编程库?
编写非阻塞、并发和可伸缩的代码是困难的。反应式编程库通过提供基于reactor模式的简单编程模型,提供了构建此类应用程序的最简单方法,这将允许应用程序高效地使用所有硬件资源。
相对于传统的基于回调和Future的异步开发方式,响应式编程更加具有可编排性和可读性,配合lambda表达式,代码更加简洁,处理逻辑的表达就像装配“流水线”,适用于对数据流的处理。
统一的编码方式,在不同的反应式网络协议和编程模型之上,构建了抽象编程层。例如gRPC和RSocket等反应式网络协议,无需了解具体协议细节,直接使用抽象层编程即可实现相关功能。
1.2 反应式编程库示例
主流反应式编程框架
- Reactor-core
- Spring-Webflux
其他反应式编程框架
- RxJava
新兴反应式框架套件
- vert.x
- Quarkus
静态编译技术:GraalVM/Android
1.3 反应式编程库和其他异步编程框架的对比
Java8
responseHandlerFuture.whenCompleteAsync((r, t) -> {
if (t == null) {
responseFuture.complete(r);
} else {
responseFuture.completeExceptionally(t);
}
}, futureCompletionExecutor);
Guava
responseFuture.addListener(() -> {...}, rpcExecutorService);
reactor
// sending with async non-blocking io
return Mono
.fromCompletionStage(() -> {
// 注①
CompletableFuture<SendEmailResponse> responseFuture = awsAsyncClient.sendEmail(sendEmailRequest);
return responseFuture;
})
// 注② thread switching: callback executor
// .publishOn(asyncResponseScheduler)
// 注③ callback: success
.map(response -> this.onSuccess(context, response))
// 注④ callback: failure
.onErrorResume(throwable -> {
return this.onFailure(context, throwable);
});
1.4 为啥不用Java Stream来进行数据流的操作?
原因在于,若将其用于响应式编程中,是有局限性的。比如如下两个需要面对的问题:
- Web 应用具有I/O密集的特点,I/O阻塞会带来比较大的性能损失或资源浪费,我们需要一种异步非阻塞的响应式的库,而Java Stream是一种同步API。
- 假设我们要搭建从数据层到前端的一个变化传递管道,可能会遇到数据层每秒上千次的数据更新,而显然不需要向前端传递每一次更新,这时候就需要一种流量控制能力,就像我们家里的水龙头,可以控制开关流速,而Java Stream不具备完善的对数据流的流量控制的能力。
具备“异步非阻塞”特性和“流量控制”能力的数据流,我们称之为反应式流(Reactive Stream)。
二、反应式编程库原理
2.1 编程理论
函数式编程风格
就像面向对象的编程思想一样,函数式编程只是一系列想法,而不是一套严苛的规定。有很多支持函数式编程的程序语言,它们之间的具体设计都不完全一样。
- 延迟执行的
- 无副作用
- 不可变变量
- 并发编程
声明式编程风格
- 结合函数式编程
- 分隔函数算子,隔离副作用
反应式编程风格
响应式编程(reactive programming)是一种基于数据流(data stream)和变化传递(propagation of change)的声明式(declarative)的编程范式。
- 函数式+声明式
- 延迟执行
- 背压
- 变化传递,推送
本质上都是java编程语言,主要区别在于编程风格和思考逻辑的不同
2.2 反应式库的核心接口
组装数据流处理链的几种形式:
1. 链表形式
面向过程
2. 观察者模式
面向对象
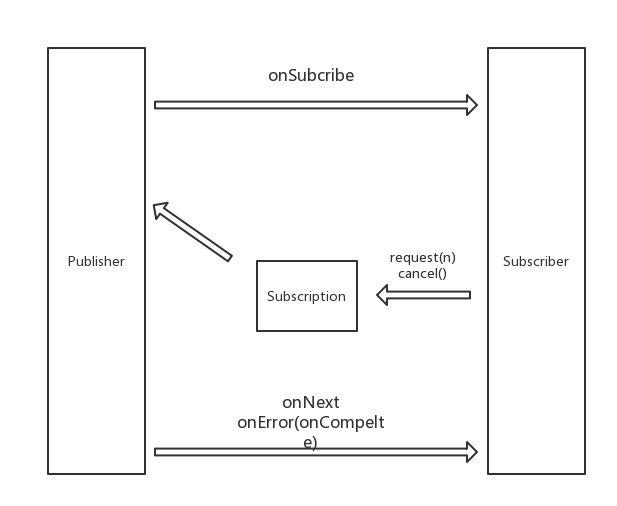
Publisher/Subscriber/Subctiption
java9
Publisher 即被观察者
Publisher 在 PRR 中 所承担的角色也就是传统的 观察者模式 中的 被观察者对象,在 PRR 的定义也极为简单。
package org.reactivestreams;
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
Publisher 的定义可以看出来,Publisher 接受 Subscriber,非常简单的一个接口。但是这里有个有趣的小细节,这个类所在的包是 org.reactivestreams,这里的做法和传统的 J2EE 标准类似,我们使用标准的 Javax 接口定义行为,不定义具体的实现。
Subscriber 即观察者
Subscriber 在 PRR 中 所承担的角色也就是传统的 观察者模式 中的 观察者对象,在 PRR 的定义要多一些。
public interface Subscriber<T> {
public void onSubscribe(Subscription s); ➊
public void onNext(T t); ➋
public void onError(Throwable t);
public void onComplete(); ➍
}
➊ 订阅时被调用 ➋ 每一个元素接受时被触发一次 ➌ 当在触发错误的时候被调用 ➍ 在接受完最后一个元素最终完成被调用
Subscriber 的定义可以看出来,Publisher 是主要的行为对象,用来描述我们最终的执行逻辑。
行为是由Subscriber触发的,这是一种Pull模型,如果是Publisher触发,则为Push模型。
Subscription 桥接者
在最基础的 观察者模式 中,我们只是需要 Subscriber 观察者 Publisher 发布者,而在 PRR 中增加了一个 Subscription 作为 Subscriber Publisher 的桥接者。
public interface Subscription {
public void request(long n); ➊
public void cancel(); ➋
}
➊ 获取 N 个元素往下传递 ➋ 取消执行
为什么需要这个对象,笔者觉得是一是为了解耦合,第二在 Reference 中有提到 Backpressure 也就是下游可以保护自己不受上游大流量冲击,这个在 Stream 编程中是无法做到的,想要做到这个,就需要可以控制流速,那秘密看起来也就是在 request(long n) 中。
中间层,主要用于解耦和流控。
2.3 实现原理概括
1. 命令式编程
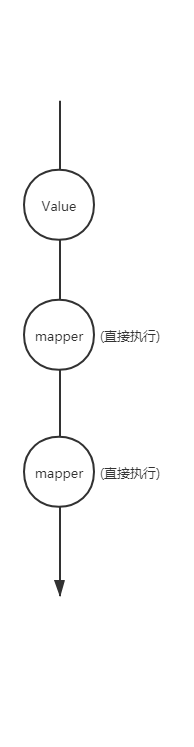
2. 声明式编程
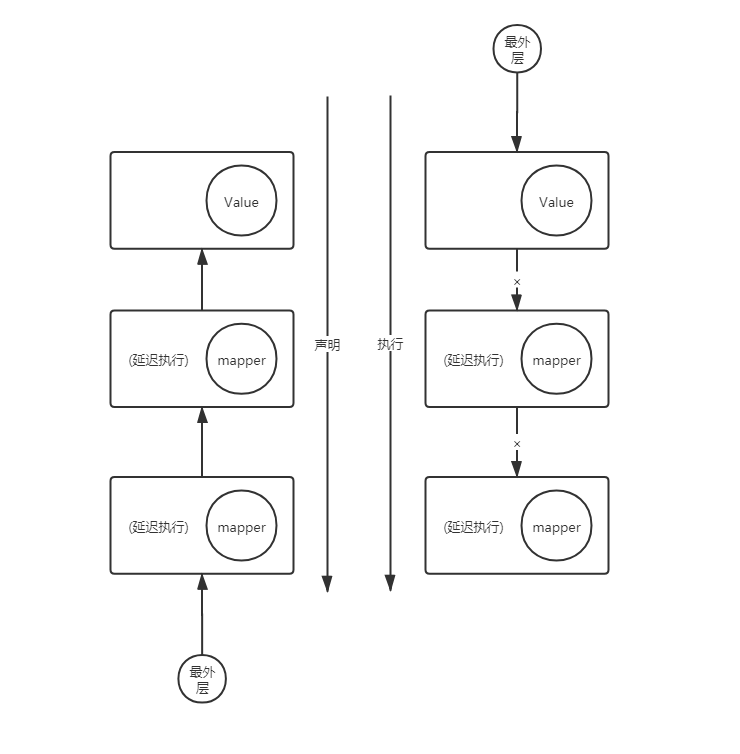
常用的、简单的数据流处理链路
Netty
3. 函数式编程 Stream
去除中间过程,横向改为纵向处理
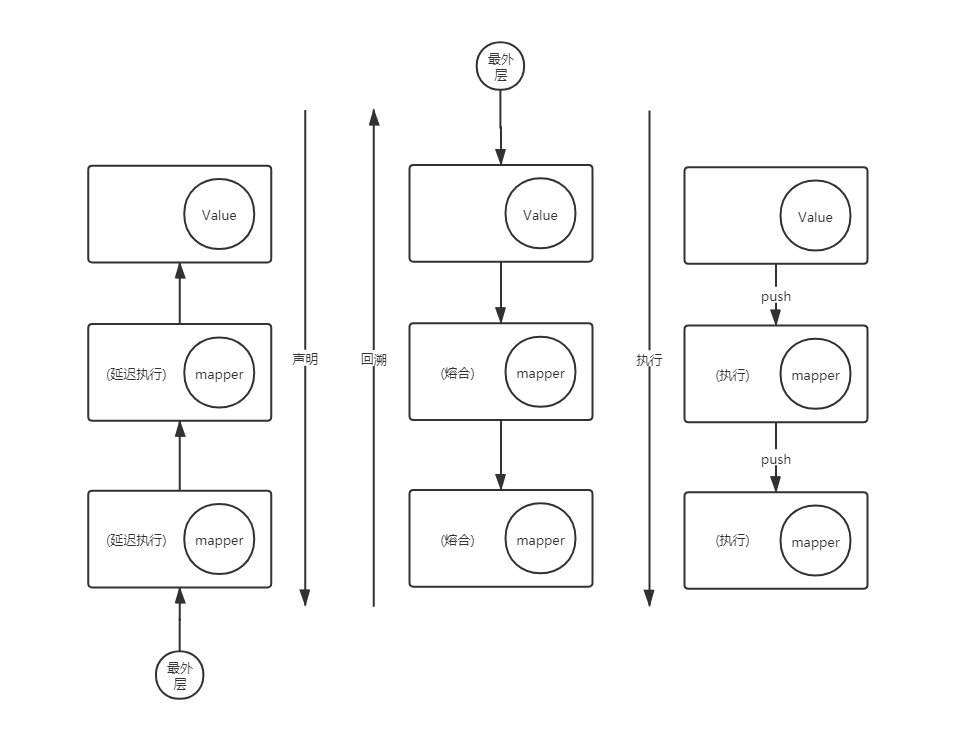
1. 声明阶段
将Op组装成Pipeline
2. 组装订阅链
生成Sink链
优化:
- 中间操作合并
- 终结操作收集数据
3. 执行阶段
执行Sink方法
最核心的就是类为AbstractPipeline,ReferencePipeline和Sink接口.AbstractPipeline抽象类是整个Stream中流水线的高度抽象了源头sourceStage,上游previousStage,下游nextStage,定义evaluate结束方法,而ReferencePipeline则是抽象了过滤,转换,聚合,归约等功能,每一个功能的添加实际上可以理解为卷心菜,菜心就是源头,每一次加入一个功能就相当于重新长出一片叶子包住了菜心,最后一个功能集成完毕之后整颗卷心菜就长大了。而Sink接口呢负责把整个流水线串起来,然后在执行聚合,归约时候调AbstractPipeline抽象类的evaluate结束方法,根据是否是并行执行,调用不同的结束逻辑,如果不是并行方法则执行terminalOp.evaluateSequential否则就执行terminalOp.evaluateParallel,非并行执行模式下则是执行的是AbstractPipeline抽象类的wrapAndCopyInto方法去调用copyInto,调用前会先执行一下wrapSink,用于剥开这个我们在流水线上产生的卷心菜。从下游向上游去遍历AbstractPipeline,然后包装到Sink,然后在copyInto方法内部迭代执行对应的方法。最后完成调用
4. 反应式编程 Reactor
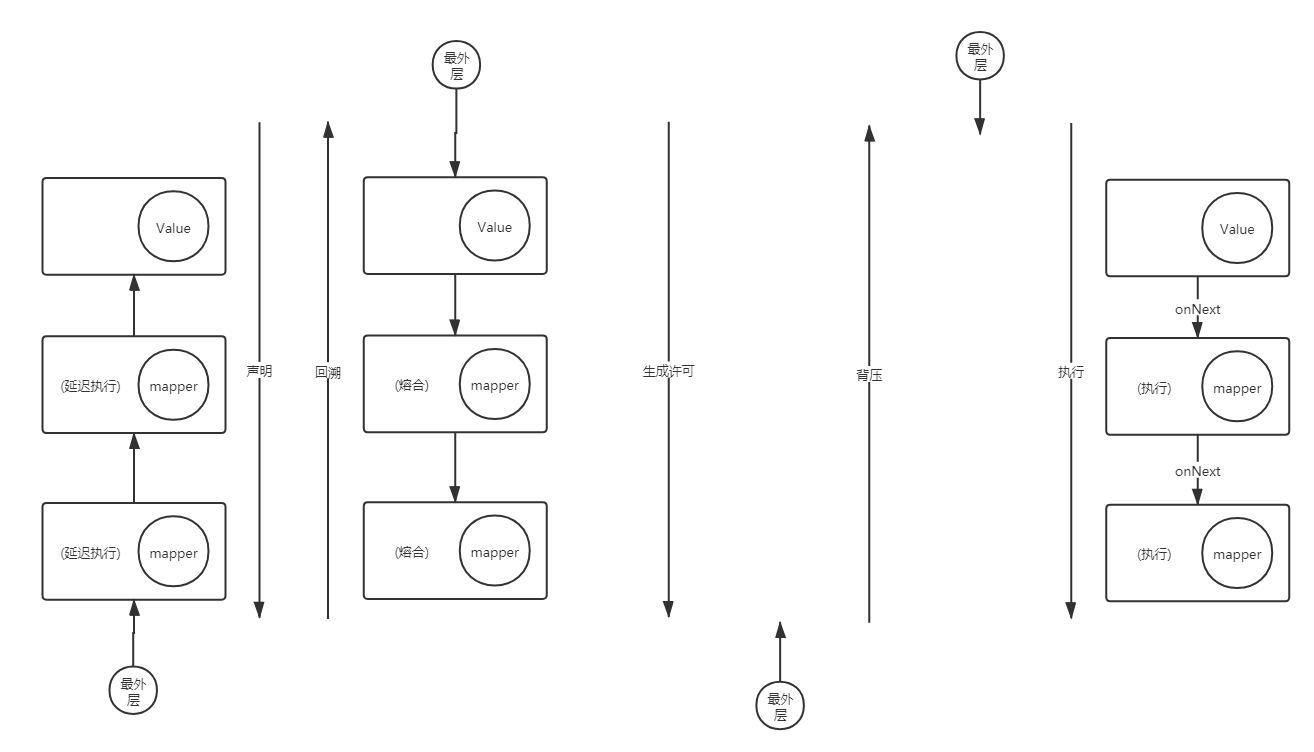
反应式编程模型在执行中主要有5条链路:
1. 声明流程
组装reactor执行链路,绑定上下游节点,在 subscribe() 之前,我们什么都没做,只是在不断的包裹 Publisher 将作为原始的 Publisher 一层又一层的返回回来。
生成Publisher
2. 组装订阅链
subscribe()
生成Subscriber
内存数据发送很简单,就是循环发送。而对于像数据库、RPC 这样的场景,则会触发请求的发送。
Publisher 接口中的 subscribe 方法语义上有些奇特,它表示的不是订阅关系,而是被订阅关系。即 aPublisher.subscribe(aSubscriber) 表示的是 aPublisher 被 aSubscriber 订阅。
对于中间过程的 Mono/Flux,subscribe 阶段是订阅上一个 Mono/Flux;而对于源 Mono/Flux,则是要执行 Subscriber.onSubscribe(Subscription s) 方法。
3. 通知:执行前初始化 + 生成许可
onSubscribe()
生成Subscription,并将Subscriber作为成员参数传入
4. 背压流程
request(n)
基于Subscription实现request(n)机制
5. 执行流程
doNext()/….
基于Subscription中的Subscriber实现执行机制
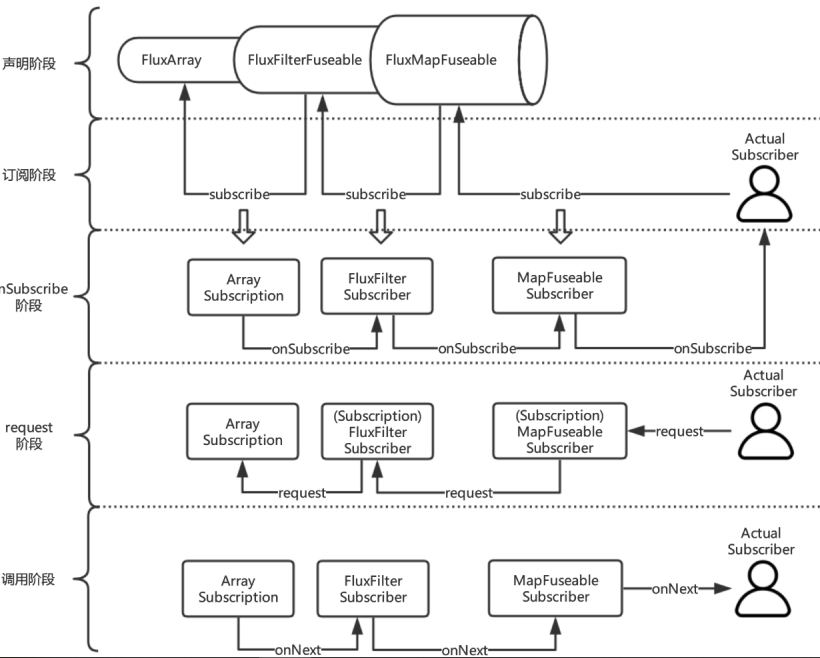
三、Reactor源码分析
3.1 Reactor-core工作原理
3.2 实现细节
- 声明阶段: 当我们每进行一次 Operator 操作 (也就 map filter flatmap),就会将原有的 FluxPublisher 包裹成一个新的 FluxPublisher
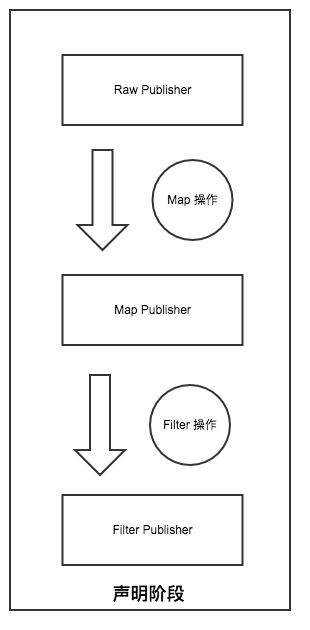
最后生成的对象是这样的
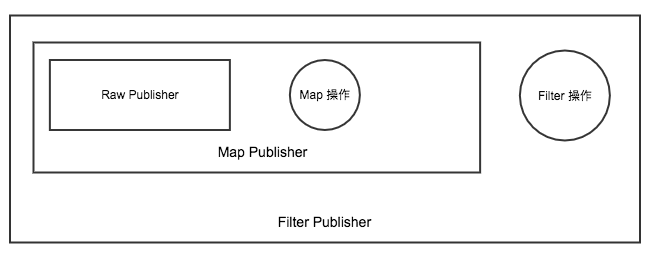
- subscribe阶段: 当我们最终进行 subscribe 操作的时候,就会从最外层的 Publisher 一层一层的处理,从这层将 Subscriber 变化成需要的 Subscriber 直到最外层的 Publisher
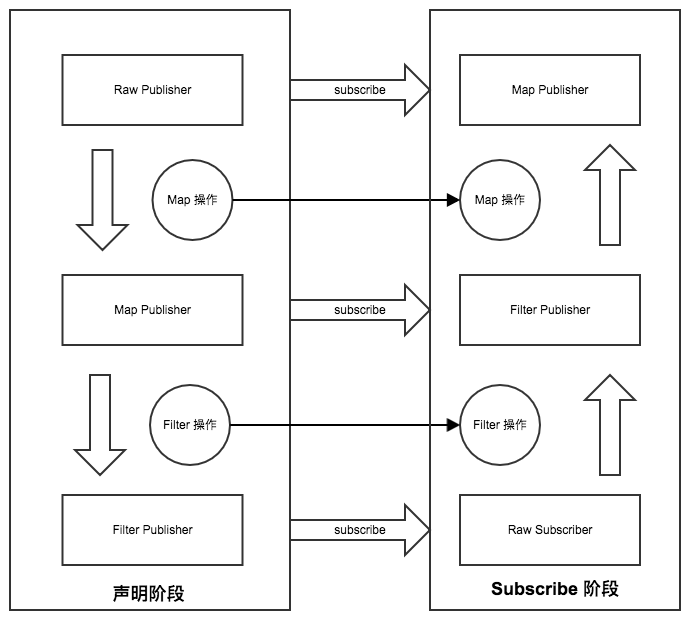
最后生成的对象是这样的
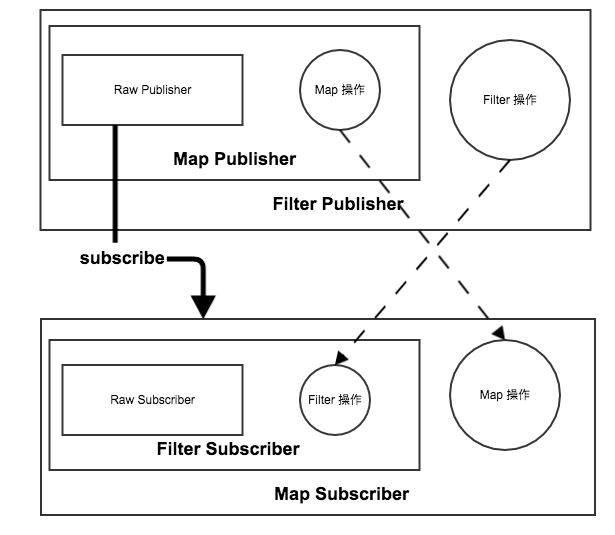
- onSubscribe阶段: 在最外层的 Publisher 的时候调用 上一层 Subscriber 的 onSubscribe 函数,在此处将 Publisher 和 Subscriber 包裹成一个 Subscription 对象作为 onSubscribe 的入参数。
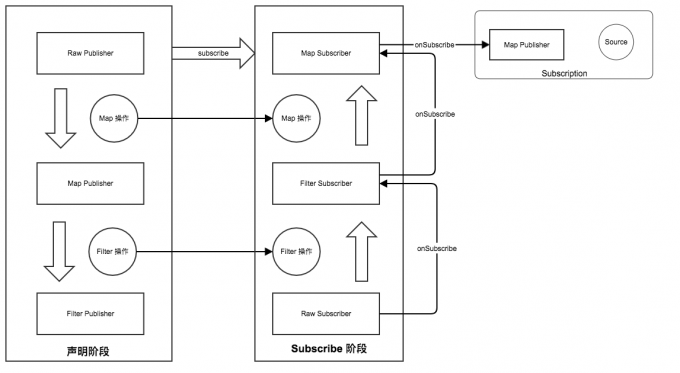
- 最终在 原始 Subscriber 对象调用 request() ,触发 Subscription 的 Source 获得数据作为 onNext 的参数,但是注意 Subscription 包裹的是我们封装的 Subscriber 所有的数据是从 MapSubscriber 进行一次转换再给我们的原始 Subscriber 的。
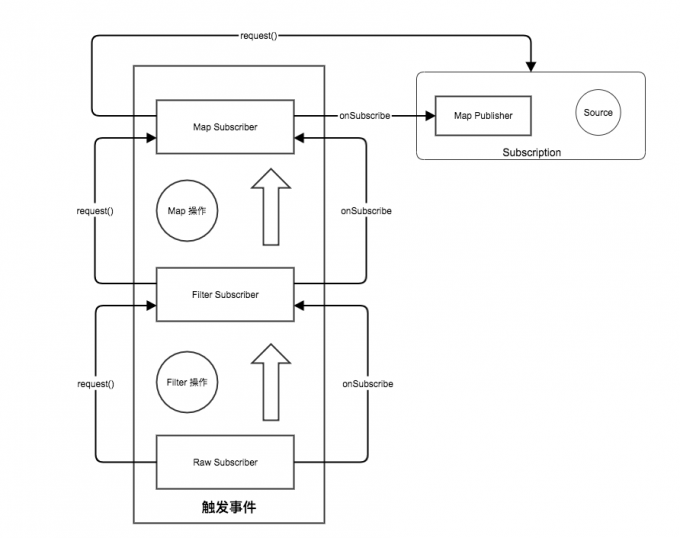
经过一顿分析,整个 PRR 是如何将操作整合起来的,我们已经有一个大致的了解,通过不断的包裹出新的 Subscriber 对象,在最终的 request() 行为中触发整个消息的处理,这个过程非常像 俄罗斯套娃,一层一层的将变化组合形变操作变成一个新的 Subscriber, 然后就和一个管道一样,一层一层的往下传递。
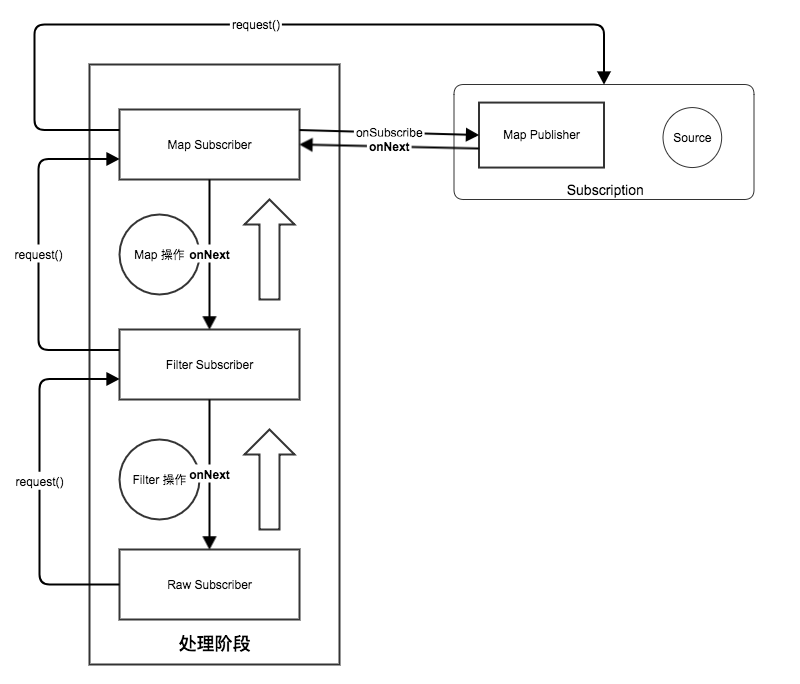
- 最终在 Subscription 开始了我们整个系统的数据处理
3.3 Reactor示例/高级用法
Reactor库提供了丰富的操作符,通过这些操作符你几乎可以搭建出能够进行任何业务需求的数据处理管道/流水线。如果将Reactor的执行步骤看做一条流水线,那么操作符就可以比作流水线中的一个工作台,负责处理流程中的元素,并传递给下游。 上述章节我们了解到Reactor的执行流程包括subscribe、onSubscribe、onRequest阶段,一个基本的操作符需要实现这些阶段的处理,比如连接上下游并往下传递,之后在onNext中实现该操作符具体的功能便可以完成一个操作。接下来我们通过学习一些操作符来了解
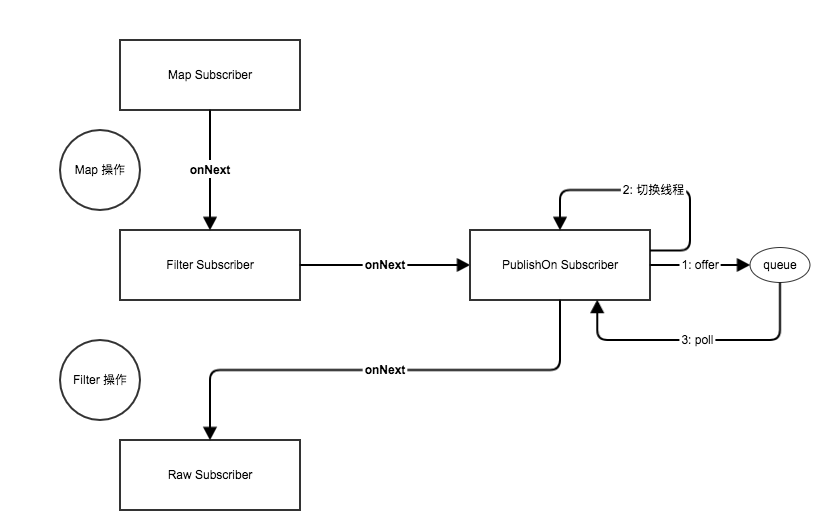
publishOn 切换线程
publishOn 强制下一个操作符(很可能包括下一个的下一个…)来运行在一个不同的线程上。
背压控制
背压指的是当Subscriber请求的数据的访问超出它的处理能力时,Publisher限制数据发送速度的能力。
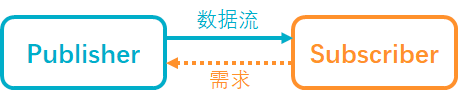
本质上背压和TCP中的窗口限流机制比较类似,都是让消费者反馈请求数据的范围,生产者根据消费者的反馈提供一定量的数据来进行流控。
反馈请求数据范围的操作,可以在Subscriber每次完成数据的处理之后,让Subscriber自行反馈;也可以在Subscriber外部对Subscriber的消费情况进行监视,根据监视情况进行反馈。 背压通常在以下场景中使用:
- 网络通信中服务端控制客户端的请求速度或发布者与订阅者不在同一个线程中,因为在同一个线程中的话,通常使用传统的逻辑就可以,不需要进行回压处理;
- 发布者发出数据的速度高于订阅者处理数据的速度,也就是处于“PUSH”状态下,如果相反,那就是“PUll”状态,不需要处理回压。
我们可以自定义subscriber,并在subscriber中使用
request(n)来通过 subscription 向上游传递 背压请求
Flux<String> source = someStringSource();
source.map(String::toUpperCase)
.subscribe(new BaseSubscriber<String>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
//在开始这个流的时候请求一个元素值。
request(1);
}
@Override
protected void hookOnNext(String value) {
//执行onnext的时候向上游请求一个元素
request(1);
}
});
3.4 Reactor流程总结
- 在声明阶段,我们像 俄罗斯套娃 一样,创建一个嵌套一个的 Publisher
- 在 subscribe() 调用的时候,我们从最外围的 Publisher 根据包裹的 Operator 创建各种 Subscriber
- Subscriber 通过 onSubscribe() 使得他们像一个链条一样关联起来,并和 最外围的 Publisher 组合成一个 Subscription
- 在最底层的 Subscriber 调用 onSubscribe 去调用 Subscription 的 request(n); 函数开始操作
- 元素就像水管中的水一样挨个 经过 Subscriber 的 onNext(),直至我们最终消费的 Subscriber
四、反应式编程总结
4.1 编程理论
- 命令式编程/面向对象编程 → 优缺点,适用场景
- 函数式编程 → 算子,副作用约束,函数式流编程
- 声明式编程 → 动词封装,逻辑清晰
- 反应式编程 → 异步非阻塞,事件驱动/消息驱动,背压
4.2 流式框架的设计
- 同步流框架设计(一线)
- 函数式流
- 异步流框架设计(二线)
- Netty等框架,声明编排
- 完善的流式框架设计(三线)
- Java Stream
- 反应式流框架设计(五线)
- 反应式编程框架,反应式网络协议
4.3 底层原理
- 异步非阻塞IO原理
- Epoll,CF
- 网络协议
- gRPC,RSocket
- 传统阻塞IO原理
- JDBC,BIO
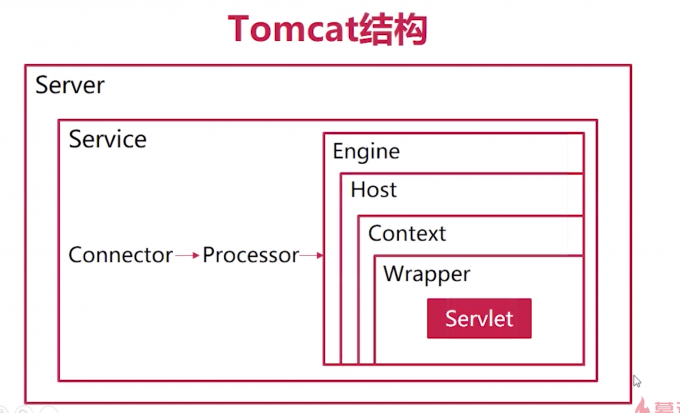
Tomcat Stack
Tomcat Devops
A、Tomcat关闭
start: INFO [Thread-7] org.apache.coyote.AbstractProtocol.pause Pausing ProtocolHandler [\"http-nio-8080\"]
start: INFO [Thread-6] org.apache.catalina.core.StandardService.stopInternal Stopping service [Catalina]
end: INFO [Thread-6] org.apache.coyote.AbstractProtocol.stop Stopping ProtocolHandler [\"http-nio-8080\"]
end: INFO [Thread-6] org.apache.coyote.AbstractProtocol.destroy Destroying ProtocolHandler [\"http-nio-8080\"]
0. 非正常关闭
start: INFO [Thread-7] org.apache.coyote.AbstractProtocol.pause Pausing ProtocolHandler [\"http-nio-8080\"]
start: INFO [Thread-6] org.apache.catalina.core.StandardService.stopInternal Stopping service [Catalina]
这是非正常关闭
1. tomcat通过脚本正常关闭(viaport: 即通过8005端口发送shutdown指令)
正常关闭(viaport)的话会在 pause 之前有这样的一句warn日志:
org.apache.catalina.core.StandardServer await
A valid shutdown command was received via the shutdown port. Stopping the Server instance.
然后才是 pause -> stop -> destory
2. tomcat的shutdownhook被触发,执行了销毁逻辑
而这又有两种情况:
- 应用代码里有地方用System.exit来退出jvm
- 系统发的信号(kill -9除外,SIGKILL信号JVM不会有机会执行shutdownhook)
- ssh会话退出
- 健康检查失败,POD触发信号